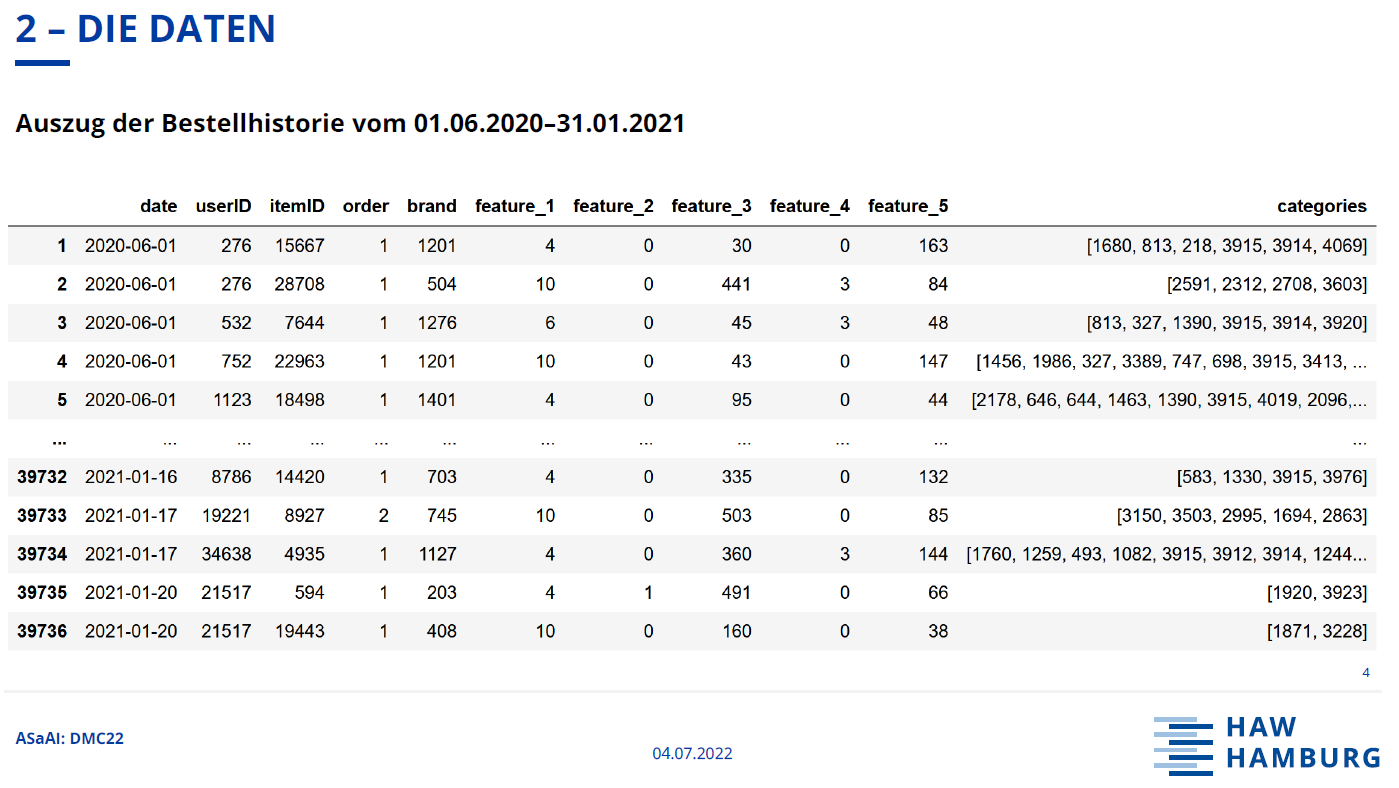
The goal of the project was to predict user-based replenishment of a product based on historical orders and item features. For a predefined subset of user and product combinations, we should predict if and when a product will be purchased during the prediction period. The time period for the data ranged from 01.06.2020 to 31.01.2021. The prediction period was between 01.02.2021 and 28.02.2021. The prediction column had to be filled like this:
- 0 – no replenishment during that period
- 1 – replenishment in the first week
- 2 – replenishment in the second week
- 3 – replenishment in the third week
- 4 – replenishment in the fourth week
We approached this by doing the following:
- Check the given data and engineer some features
- Clean the data
- Transform the data
- Compare different models
- Check if chosen model makes reasonable predictions and adjust accordingly
Tools and libraries we used during the project:
- Python including Pandas, Numpy, Matplotlib, Scikit-learn and XGBoost
- Knime
Models we tested:
- XGBoost (regression & classification)
- Linear Regression
- Random Forest
Our approach:
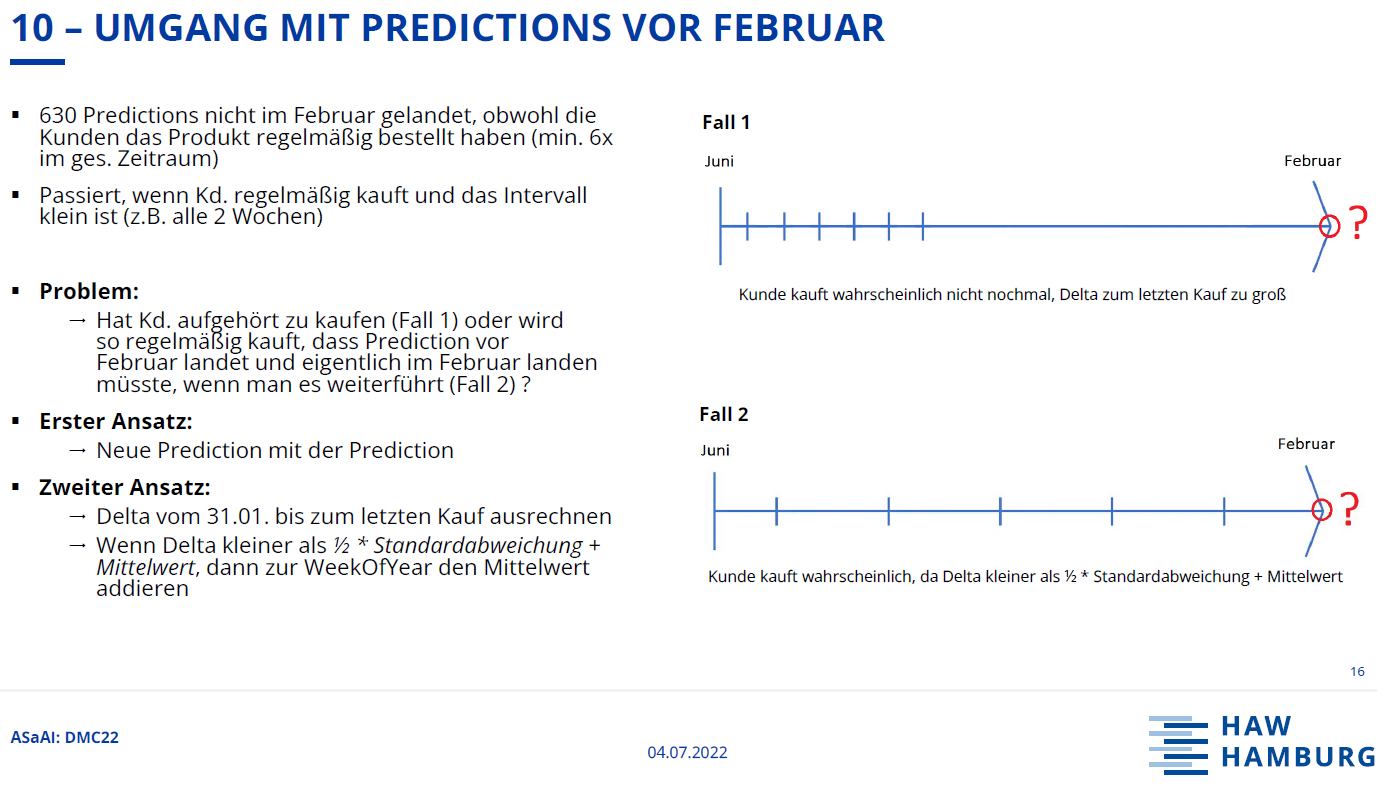
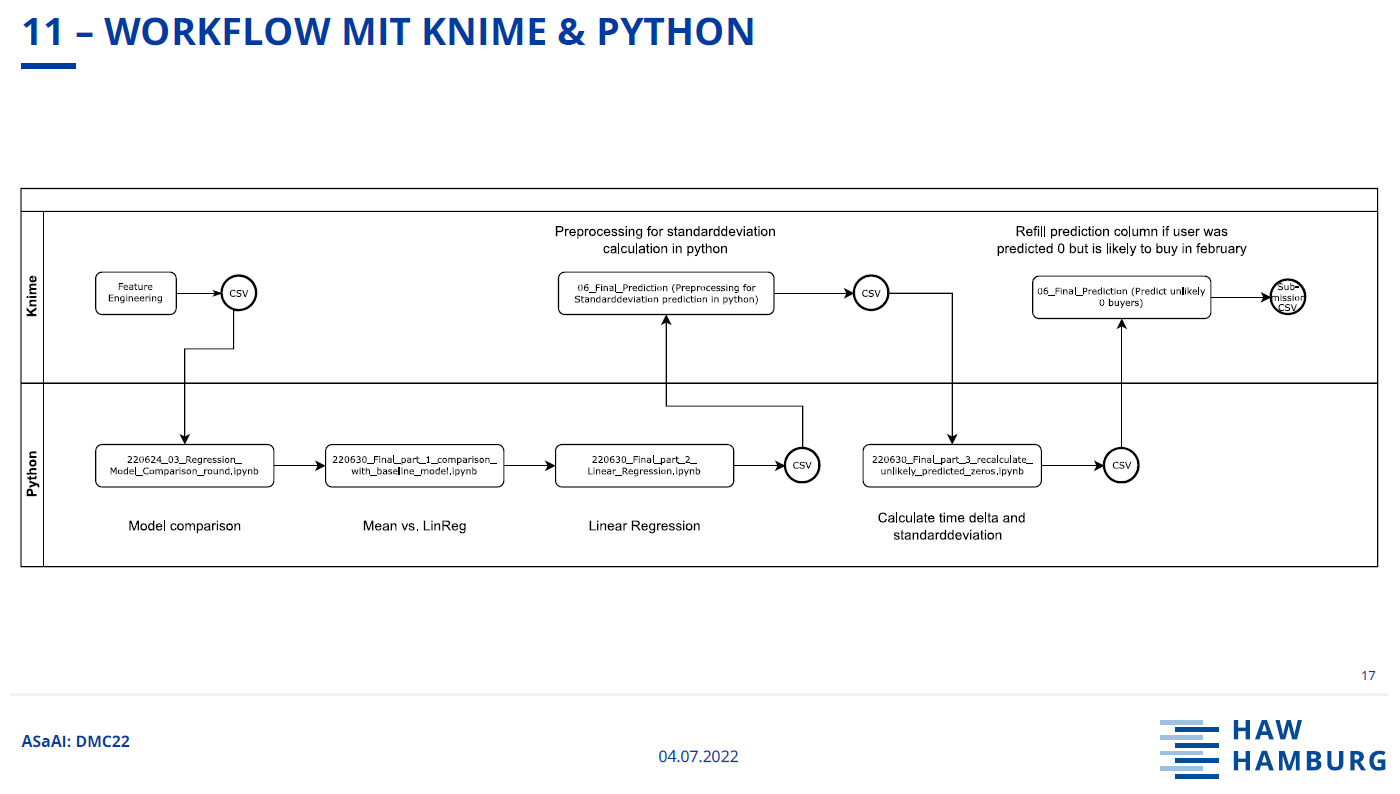
After testing different models, we decided to go with linear regression. After the models prediction we took a look at the results and realized that some predictions that should have landed in the prediction period did not. This happened for example, if a customer purchased the product regularly and the mean time between purchases was small e.g., 3 weeks. We then calculated the delta from the date where a customer could make the last purchase (31.01.2021) to his last purchase. If the delta was smaller than ½ times the standard deviation plus the mean time between purchases, we added the mean time between purchases on top of the models prediction.
Summary:
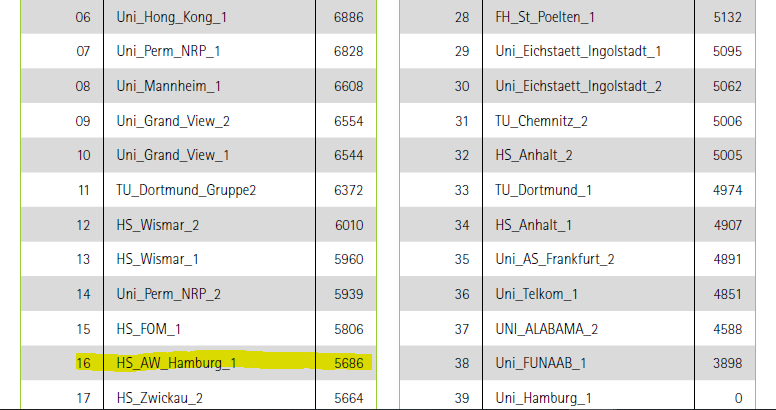
In the end we finished in 16th place out of 78 participants. It was a great learning experience, where we learned a lot about different data science techniques and that solving real-world problems is a lot harder than it seems at first sight.
What I've learned
- Technical constraints can be circumvented, through intelligent data transformation (or more compute power ;-))
- It's beneficial to test different methodologies early in the project
- Always check results for plausibility
- Using machine learning libraries like Scikit-Learn